| JUC并发编程之ForkJoin框架原理解析 | 您所在的位置:网站首页 › juc 学习 › JUC并发编程之ForkJoin框架原理解析 |
JUC并发编程之ForkJoin框架原理解析
|
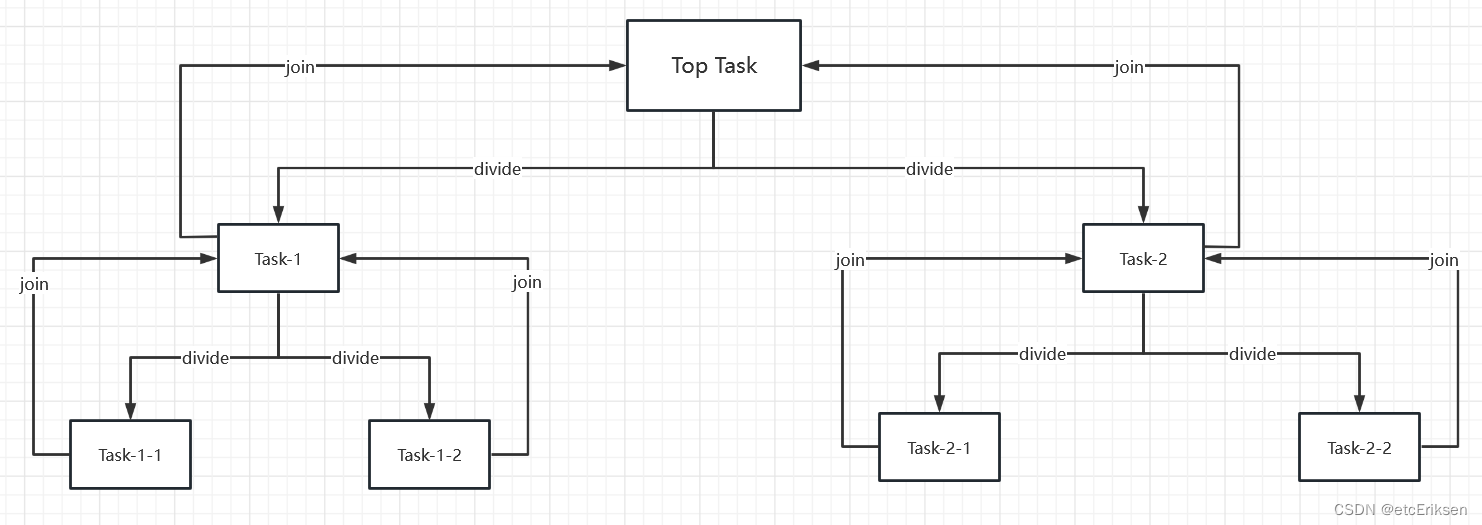
目录 JUC并发编程之ForkJoin框架原理解析 CPU密集型(CPU-bound) IO密集型(I/O bound) CPU密集型 vs IO密集型 Fork/Join 框架概念 工作窃取算法 总结 JUC并发编程之ForkJoin框架原理解析 CPU密集型(CPU-bound)CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/内存),I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU Loading很高。 在多重程序系统中,大部份时间用来做计算、逻辑判断等CPU动作的程序称之CPU bound。例如一个计算圆周率至小数点一千位以下的程序,在执行的过程当中绝大部份时间用在三角函数和开根号的计算,便是属于CPU bound的程序。 CPU bound的程序一般而言CPU占用率相当高。这可能是因为任务本身不太需要访问I/O设备,也可能是因为程序是多线程实现因此屏蔽掉了等待I/O的时间。 线程数一般设置为: 线程数 = CPU核数+1 (现代CPU支持超线程) IO密集型(I/O bound)IO密集型指的是系统的CPU性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是CPU在等I/O (硬盘/内存) 的读/写操作,此时CPU Loading并不高。 I/O bound的程序一般在达到性能极限时,CPU占用率仍然较低。这可能是因为任务本身需要大量I/O操作,而pipeline做得不是很好,没有充分利用处理器能力。 线程数一般设置为: 线程数 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目 CPU密集型 vs IO密集型我们可以把任务分为计算密集型和IO密集型。 计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。 计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。 第二种任务的类型是IO密集型,涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。 IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。 Fork/Join 框架概念Fork/Join 框架是 Java7 提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。 Fork 就是把一个大任务切分为若干子任务并行的执行,Join 就是合并这些子任务的执行结果,最后得到这个大任务的结果。比如计算1+2+.....+10000,可以分割成 10 个子任务,每个子任务分别对 1000 个数进行求和,最终汇总这 10 个子任务的结果。如下图所示:
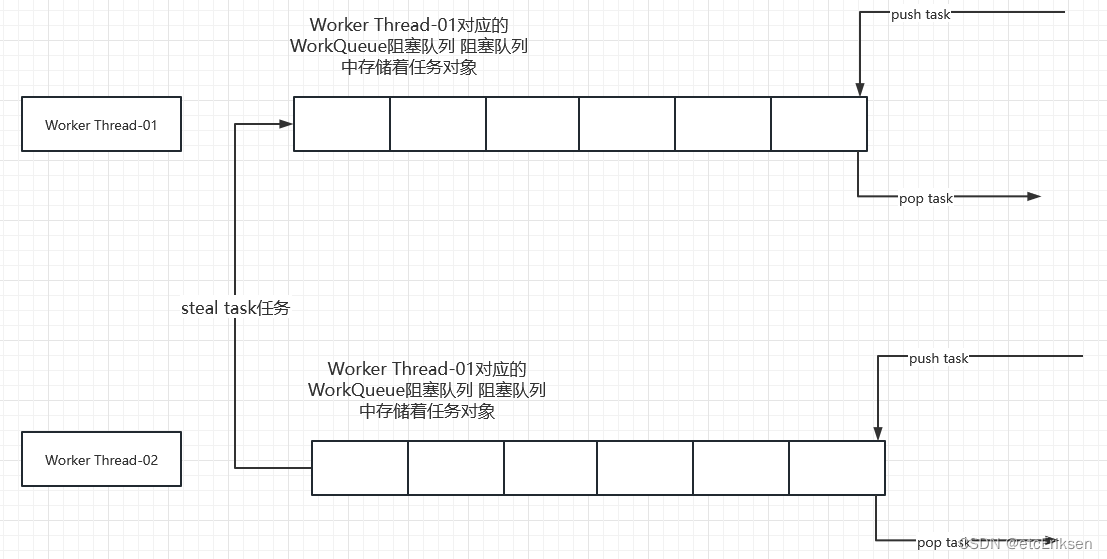
Fork/Jion特性: ForkJoinPool 不是为了替代 ExecutorService,而是它的补充,在某些应用场景下性能比 ExecutorService 更好。(见 Java Tip: When to use ForkJoinPool vs ExecutorService )ForkJoinPool 主要用于实现“分而治之”的算法,特别是分治之后递归调用的函数,例如 quick sort 等。ForkJoinPool 最适合的是计算密集型的任务,如果存在 I/O,线程间同步,sleep() 等会造成线程长时间阻塞的情况时,最好配合使用 ManagedBlocker 工作窃取算法工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。 我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。 工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
Fork Join框架适用于千万级的数据运算,因为它需要大量的线程切换开销。在万级别数据量下使用单线程的运算效率高于Fork Join框架fork多线程处理的效率。 在实际生产中极少使用,理解其中所使用到的原理即可 |
【本文地址】